Nobody informs you of the uploaded files on moodle, so everyday you have to check every webpage of courses and folders? Using MoodleHelper, you can see everything just on the frontpage!
When doing quizzes, you feel tired to “click the right answer + click check button + scroll to the next question” for every question? Using MoodleHelper, all you need to do is press the ABCD on your keyboard!
EBP Essay requires less than 9 (or 8) words in a sentence, but you sometimes didn’t follow it by accident, and didn’t notice that? Use EssaySentenceLengthChecker, and it will mark every sentence of that kind!
I have currently developed an extension called “Moodle Helper”. And I also developed a tool called “EssaySentenceLengthChecker” about EBP courses. Both are in the hope that it will be more convenient for everyone.
Installation:
MoodleHelper: Use your computer’s Chrome Browser to visit the website below, then click the “Add to Chrome” button on the top right corner. Then you can visit Moodle and start using it :)
There will be a cooperation with ITSO department. So here are the functions that may be added in the future:
Intelligent Printing: You just need to click the ppt on Moodle. Then the system will compose and arrange automatically (e.g. print 8 slides tightly onto one piece of paper, print both sides of paper, …), and then send it to the printer automatically. So I think it will be convenient and will save paper. (P.S. It seems that 90% people here don’t know that ppt can be printed to a piece of paper very tightly without lots of blank)
Intelligent Synchronize: Automatically sync the files on Moodle to the folders in your computer. So you will never need to download new files and put them into corresponding folders.
Some common questions:
Why there is no Safari version: The registry costs 99 dollar per year, so if any warm-hearted man can give me an account, I will develop it immediately!
Is it only available on Chrome: 360 Browser and QQ Browser may be available too.
Is the software safe: Moodle Helper is a fully open-sourced software. So if you think it is not safe, you can just see the source code. And you are welcome to contribute new functions and codes to this project!
Want to preview ppts, but you don’t know when the professor will upload their ppts, so you have to refresh and see every course page on Moodle over and over again?
The professor likes to upload files into folders, so you have to open every one of them to see whether there are new things?
A new assignment appears “mysteriously” without notification, and you don’t notice the tiny new line appended on the course page?
…
This is just a small tool I made in my spare time, so there inevitably exists some insufficiency and please excuse that in my tool. If you have other questions, you are welcome to contact me at any time! (The contact information is listed below.)
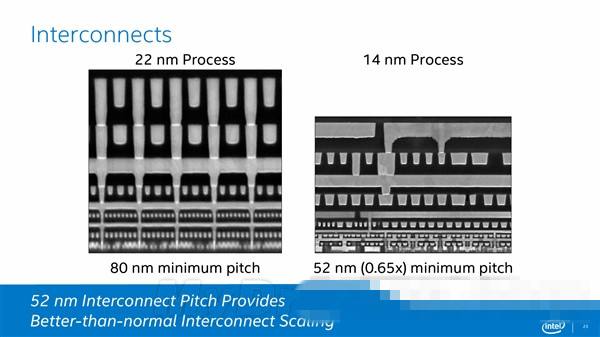
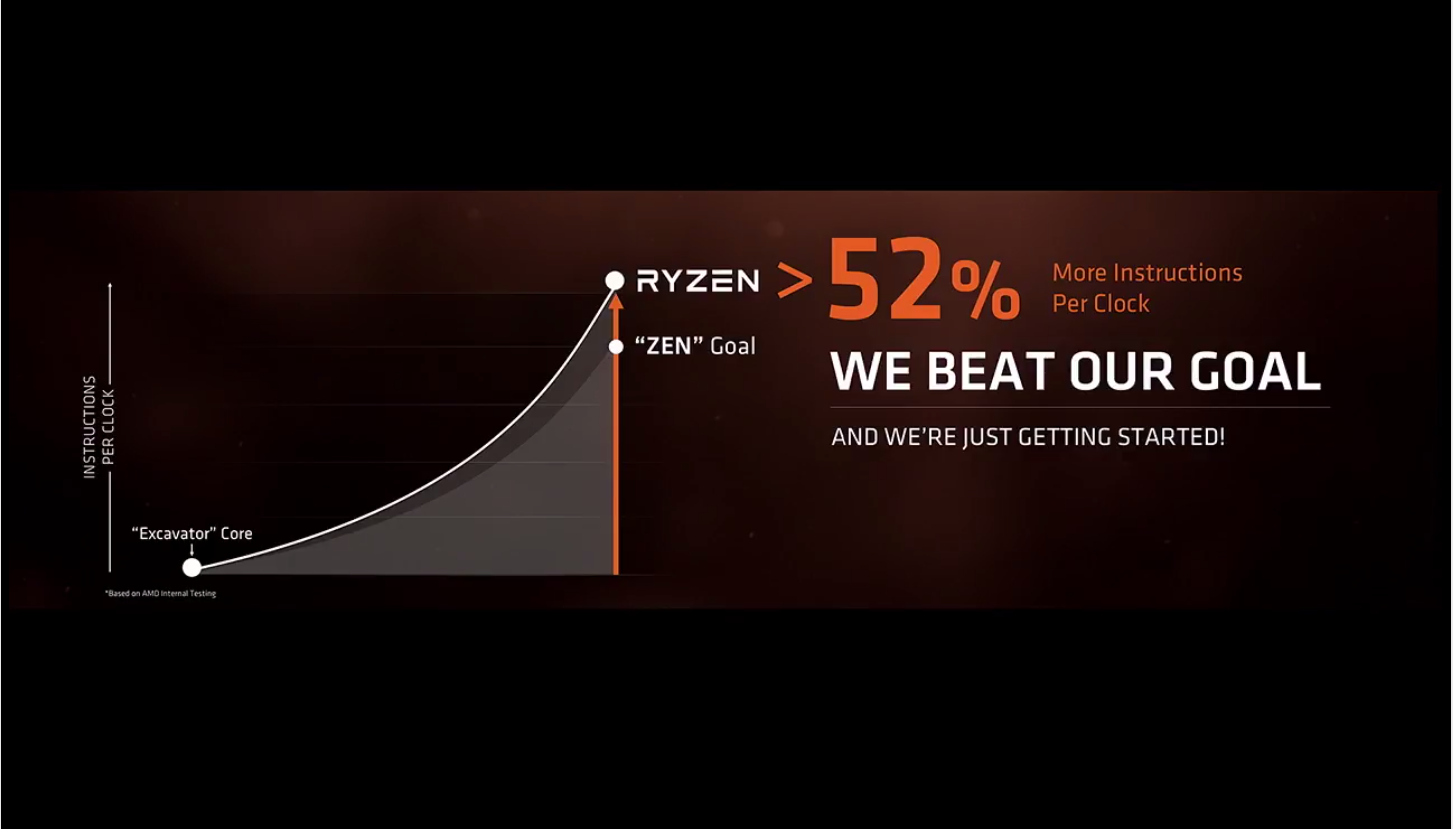
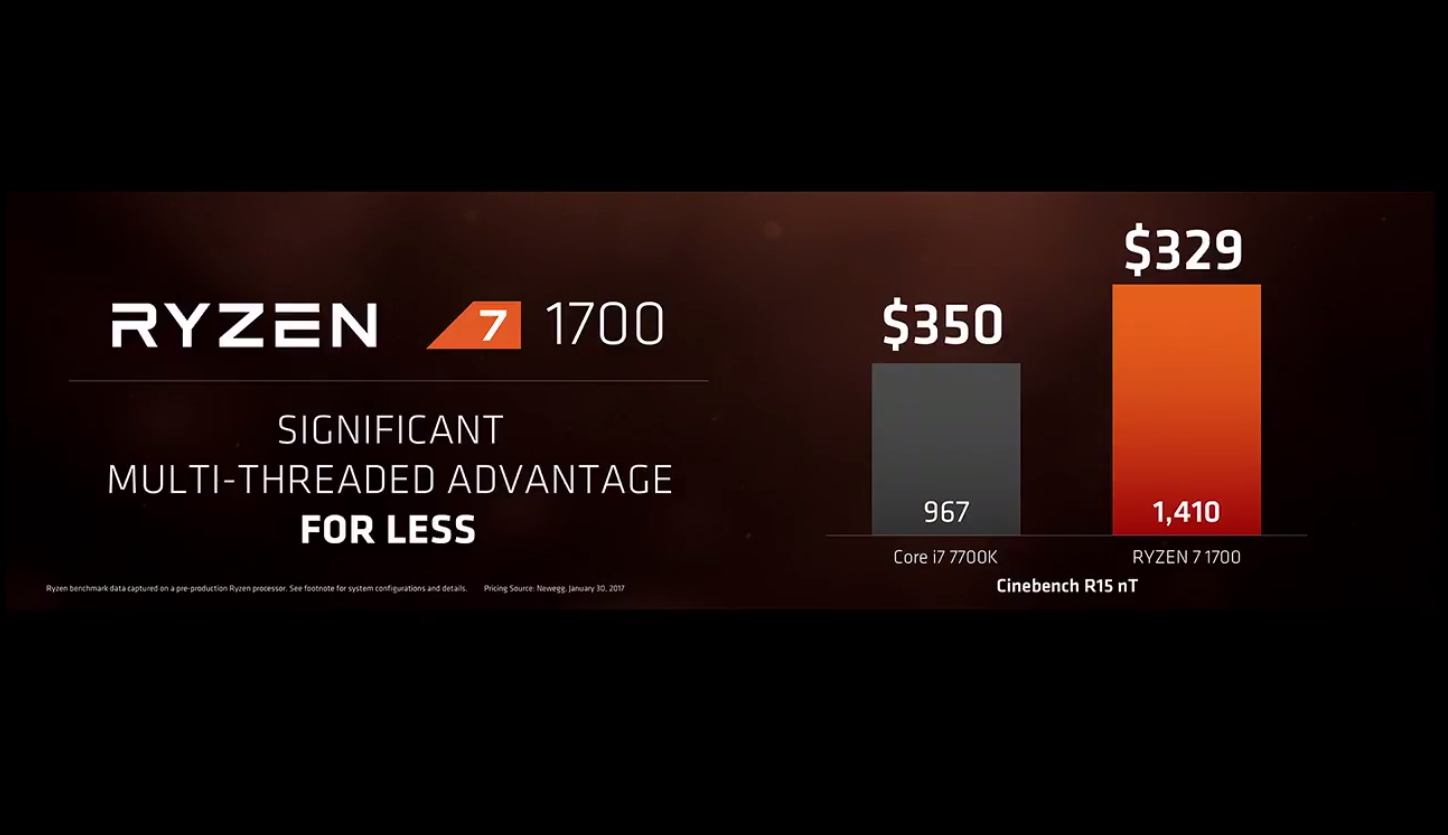
近几年,桌面级 CPU 的发展相当缓慢,这是多方面的原因所造成的:桌面级 CPU 的市场一直为英特尔(Intel)和 AMD 所控制,而整整 10 年, AMD 一直被英特尔压一头,使得英特尔独步天下,几乎完全占有了桌面级电脑 CPU 市场;随着 CPU 制造工艺的进化,工艺改进越来越难(特别是最近各个代工厂商的 10nm 制程都出现了良品率不高的问题),使得直接细化电路来改进 CPU 受阻;改进架构、多核多线程化当然可以提升 CPU 性能,但整体极弱的市场竞争,也使得英特尔看不到拉升桌面级 CPU 性能的必要性。
Suppose we have data set S=(x(i),y(i)),i=1,…,m where x(i)∈Rn such that x has n features with m training examples. Let us assume that the target variables and the inputs are related via a linear equation.
y(i)=θTx(i)+ϵ(i)
Where ϵ(i) is an error term that captures either un-model effects or random noise. Let’s assume that the ϵ(i)’s are distribute i.i.d.(independently and identically distributed) according to Gaussian Distribution with mean zero and variance σ2. Which can be written as ϵ(i)∼N(0,σ2). And the pdf of ϵ(i) is given by
p(ϵ(i))=1√2πσ(−(ϵ(i))22σ2)
Because of ϵ(i)=y(i)−θTx(i), the pdf also can be given as
p(y(i)|x(i);θ)=1√2πσ(−(y(i)−θTx(i))22σ2)
Notice that the notation ‘p(y(i)|x(i);θ)’ indicates that this is the distribution of y(i) given x(i) is parameterized by θ and θ is not a random variable, the formula is not a probability consition on θ. We can write the distribution as ‘y(i)|x(i);θ∼N(θTx(i),σ2)’. Given an input matrix X=(x(1),x(2),…,x(m))T and θ, what the distribution of y(i)’s is given by p(→y|X;θ). When we wish to explicity view this as a function of θ, we call it the likelihood function:
L(θ)=L(θ;X,→y)=p(→y|X;θ)
Note that by the independence assumption on the ϵ(i)’s, this can be written by
Now, given this probabilistic model relating the y(i)’s and the x(i)’s. The principal of maximum likelihood says that we should should choose θ so as to make the data as high probability as possible. So We are facing an optimization problem.
maxθL(θ)
We define a new likelihood function called log likelihood:
And the maximization problem maxθℓ(θ) become a minimization problem:
minθ12m∑i=1(y(i)−θTx(i))2
This is our original least-squares cost function. Under the previous probabilistic assumptions on the data, least-squares regression corresponds to finding the maximum likelihood estimate of θ.
Back to over Linear Regression problem, assume we have data set S=(x(i),y(i)),i=1,…,m , and our hypothesis hθ(x)=θTx (we set x0 to be 1 so that the constant θ0 could be include into θ and thus x(i)∈R(n+1),θ∈R(n+1)). Notice that in our hypothesis, the θ is not the population parameter, this is the parameter we are going to estimate by maximize likelihood function. According to the probability analysis above, we define the cost function
J(θ)=12m∑i=1(hθ(x(i))−y(i))2
And the linear regression problem can be express as this optimization problem
minθJ(θ)
Let’s rewrite this problem with a simple form by matrix, denote X=(x(1),x(2),…,x(m))T, y=(y(1),y(2),…,y(m)) where x(i)∈R(n+1),y∈R(n+1) and θ∈R(n+1). So the problem can be expressed by
minθ‖Xθ−y‖22
And the linear model of inputs X can be shown as y=θTx, where θ=argminθ|Xθ−y|22. We will solve this question latter.
Least Square Linear Regression
If we want to build a model which can fit the sample data with least error, a simple way is to make the different between the estimator and the samples to be smallest in some form. In the least square linear regression, we optimize the square of the errors. Suppose we have hypothesis hθ=Xθ (in the form of matrix, where X∈Rm∗(n+1) and θ∈R(n+1), x(i)0=1 for all the inputs to make θ0 to be constant), the problem can be expressed in the form
minθ‖Xθ−y‖22
This is same with the maximize likelihood regression in expression but they have differences. In maximize likelihood estimation we have an important assumption that all the samples x(1),x(2),…,x(m) are i.i.d. The θ is the parameter of the model, h is our model or our hypothesis. With regard to maximizing likelihood regression, the most reasonable estimation should be the one which makes the probability of n samples extracted from the model observe those y’s maximum. But for least square, the most reasonable estimation is the one which can fit the samples best(the minimum of the square of error). It is clear that those regression method are come from different idea.
When we employ maximize likelihood regression, we need to know the probability distribution of errors or the hypothesis. In general, we assume that the distribution is Gaussian. Under this assumption, maximize likelihood regression is equivalent to least square regression.
For least square, we can also try to understand it in the form of geometry. Suppose we have a vector space N∈R(n+1) and all the input sample x(i) is in this space. In this regression problem, the real thing we want is to find one way that hold x(i)θ=y(i) for all m samples, which can be written as Xθ=y. But in real world problems the most likely situation is the number of samples m is larger than the features n which indicates that the equation Xθ=y will be overdetermined. Assume the solution of this least square problem is θ′ and Xθ′ is the orthogonal projection y project to the space spanned by X’s column vector. And in linear algebra the orthogonal projection from y to Xθ′ is X(XTX)−1XTy. The solution can be expressed by θ′=(XTX)−1XTy easily. We will see that this is same with the solution we solve by taking the differential later.
Solve minθ|Xθ−y|22
Except the least square solution of the overdetermined system, we can solve this by other way. With respect to |Xθ−y|22 we have J(θ)=(Xθ−y)T(Xθ−y) and the optimization problem will be
Computer is built to help people solve problems, but computer does not understand what we say. So we need to communicate with computers using their languages (computer programming language)
Components in a computer
Central processing unit (CPU): execute your program. Similar to human brain, very fast but not that smart
Input device: take inputs from users or other devices
Output device: output information to users or other devices
Main memory: store data, fast and temporary storage
Secondary memory: slower but large size, permanent storage
What can a computer actually understand
The computers used nowadays can understand only binary number (i.e. 0 and 1)。 Computers use voltage levels to represent 0 and 1 The instructions expressed in binary code is called machine language
Low level language – Assembly Language
An assembly language is a low-level programming language, in which there is a very strong (generally one-to-one) correspondence between the language and machine code instructions. Each assembly language is specific to a particular computer architecture Assembly language is converted into executable machine code by a utility program referred to as an assembler
High-level languages: C, C++, Java, Python…
High level languages cannot be executed directly High level languages must be converted into low level languages first Lower level languages have higher language efficiency (they are faster to run on a computer) Higher level languages have higher development efficiency (it is easier to write programs in these languages)
Memory and addressing
A computer’s memory consists of an ordered sequence of bytes for storing dataEvery location in the memory has a unique address
The key difference between high and low level programming languages is whether programmer has to deal with memory addressing directly
Operating Systems
The operating system (OS) is a low level program, which provides all basic services for managing and controlling a computer’s activities
Applications are programs which are built based upon an OS
Main functions of an OS:
Controlling and monitoring system activities
Allocating and assigning system resources
Scheduling operations
Popular OS: Windows, macOS, Linux, iOS, Android (a kind of Linux)…
The units of information (data)
Bit (比特/位): a binary digit which takes either 0 or 1 Bit is the smallest information unit in computer programming
Byte (字节): 1 byte = 8 bits, every English character is represented by 1 byte
KB (千字节):1 KB = 2^10 B = 1024 B
MB (兆字节):1MB = 2^20 B = 1024 KB
GB (千兆字节):1GB = 2^30 B = 1024 MB
TB (兆兆字节):1TB = 2^40 B = 1024 GB
Number Systems
A numeral system (or system of numeration) is a writing system for expressing numbers; that is, a mathematical notation for representing numbers of a given set, using digits or other symbols in a consistent manner.
Each positional number system contains two elements, a base and a set of symbols. Using the decimal system as an example, its base is 10 and the symbols are, of course, numbers.
Commonly, decimal number system, binary number system and hexadecimal number system are used in computer.
Demical Number System
In the decimal number system, the base is 10, the symbols include 0, 1, 2, 3, 4, 5, 6, 7, 8, 9
Every number can be decomposed into the sum of a series of numbers, each is represented by a positional value times a weight
𝑎𝑛 is the positional value (ranging from 0 to 15), while 16𝑛 represents the weight.
Number System Conversion
There are many methods or techniques which can be used to convert numbers from one base to another.
Decimal to Other Base System
Step 1 − Divide the decimal number to be converted by the value of the new base.
Step 2 − Get the remainder from Step 1 as the rightmost digit (least significant digit) of new base number.
Step 3 − Divide the quotient of the previous divide by the new base.
Step 4 − Record the remainder from Step 3 as the next digit (to the left) of the new base number.
Repeat Steps 3 and 4, getting remainders from right to left, until the quotient becomes zero in Step 3.
The remainders have to be arranged in the reverse order so that the first remainder becomes the Least Significant Digit (LSD) and the last remainder becomes the Most Significant Digit (MSD).
Example
Decimal Number: 29 -> Binary Equilvalent
Step
Operation
Result
Remainder
Step 1
29 / 2
14
1
Step 2
14 / 2
7
0
Step 3
7/2
3
1
Step 4
3/2
1
1
Step 5
1/ 2
0
1
Binary Number: 11101
Other Base System to Decimal System
Step 1 − Determine the column (positional) value of each digit (this depends on the position ofthe digit and the base of the number system).
Step 2 − Multiply the obtained column values (in Step 1) by the digits in the corresponding columns.
Step 3 − Sum the products calculated in Step 2. The total is the equivalent value in decimal.
Example
Binary Number: 11101 -> Decimal Equivalent
(1x24)+(1x23)+(1x22)+(1x21)+(1x20)=16+8+4+0+1=29
Decimal Fraction to Binary
You can convert a decimal fraction to binary by repeatedly multiplying the fractional results of successive multiplications by 2. The carries form the binary number.
How a program runs?
A computer doesn’t actually understand the phrase ‘Hello, world!’, and it doesn’t know how to
display it on screen. It only understands on and off. So to actually run a command like print ‘Hello, world!’, it has to translate all the code in a program into a series of ons and offs that it can understand.
To do that, a number of things happen:
The source code is translated into assembly language.
The assembly code is translated into machine language.
The machine language is directly executed as binary code.
Confused? Let’s go into a bit more detail. The coding language first has to translate its source code into assembly language, a super low-level language that uses words and numbers to represent binary patterns. Depending on the language, this may be done with an interpreter (where the program is translated line-by-line), or with a compiler (where the program is translated as a whole).
The coding language then sends off the assembly code to the computer’s assembler, which converts it into the machine language that the computer can understand and execute directly as binary code.
Interpreter (解释器) is a computer program that directly executes, i.e. performs, instructions written in a programming or scripting language, without previously compiling them into a machine language program
A compiler (编译器) is a computer program (or a set of programs) that transforms source code written in a programming language (the source language) into another computer language (the target language), with the latter often having a binary form known as object code
Introduction to Python
What & Why is Python?
Python is a widely used high-level, general-purpose, interpreted, dynamic programming language. Its design philosophy emphasizes code readability, and its syntax allows programmers to express concepts in fewer lines of code than would be possible in languages such as C++ or Java. The language provides constructs intended to enable clear programs on both a small and large scale.
Python supports multiple programming paradigms, including object-oriented, imperative and functional programming or procedural styles. It features a dynamic type system and automatic memory management and has a large and comprehensive standard library.
Python interpreters are available for many operating systems, allowing Python code to run on a wide variety of systems. Using third-party tools, such as Py2exe or Pyinstaller, Python code can be packaged into stand-alone executable programs for some of the most popular operating systems, so Python-based software can be distributed to, and used on, those environments with no need to install a Python interpreter.
CPython, the reference implementation of Python, is free and open-source software and has a community-based development model, as do nearly all of its variant implementations.
Install Python 3
In this course, we will use Python 3.5. Before we formally start the course, Python 3 must be installed in your computer first.
If you do not know how to use PowerShell on Windows, Terminal on OS X or bash on Linux then you need to go learn that first.
Follow the instruction to install Homebrew, including xcode-command
After you installed it, type in brew install python3 virtualenv
Type in python3 -V, if it shows Python 3.5.2 then everything is done.
Linux Users:
Use your package manager to install Python 3
Python Syntax
Python uses indentations to identify different program blocks. Here we show a simple example of Python script.
1 2 3 4 5 6 7 8 9 10 11 12 13
import os from datetime import *
defhelloworld(name): if len(name) != 0: return"Hello World " + name else: return"Oh my god"
if __name__ == "__main__": print(helloworld("Computer @nd Comity")) print(datetime.now())
Can you guess what will be on display?
Hello World Computer @nd Comity
2016-10-13 15:22:24.510837
Why? We will explain it in future courses.
IDE
What is IDE? An integrated development environment (IDE) is a software application that provides comprehensive facilities to computer programmers for software development. An IDE normally consists of a source code editor, build automation tools and a debugger. Most modern IDEs have intelligent code completion.
Here, we recommend you to use PyCharm when you believe that you master Python. It is a commercial software by JetBrains. Shall we pay for it? No. As a student, we can enjoy the educational promotion.
Describe what is going to happen in a sequence of code
Document who wrote the code and other important information
Turn off a line of code – usually temporarily
Variable
A variable is something that holds a value that may change. In simplest terms, a variable is just a box that you can put stuff in. You can use variables to store all kinds of stuff, but for now, we are just going to look at storing numbers in variables.
Rules for defining variables in Python
Must start with a letter or underscore , Can only contain letters, numbers and underscore, Case sensitive
Reserved words
The following identifiers are used as reserved words, or keywords of the language, and cannot be used as ordinary identifiers. They must be spelled exactly as written here:
False
class
finally
is
return
None
continue
for
lambda
try
True
def
from
nonlocal
while
and
del
global
not
with
as
elif
if
or
yield
assert
else
Import
pass
break
except
in
raise
Assign a variable
1
a = "HELLO"
Multiple Assignment
Python allows you to assign a single value to several variables simultaneously. For example −
1
a = b = c = 1
Here, an integer object is created with the value 1, and all three variables are assigned to the samememory location. You can also assign multiple objects to multiple variables. For example −
1
a, b, c = 1, 2, "john"
Here, two integer objects with values 1 and 2 are assigned to variables a and b respectively, and onestring object with the value “john” is assigned to the variable c.
Extensive Knowledge
When you assign to a variable you are binding the name to an object. From that point onwards you can refer to the object by using the name, until that name is rebound.
In the first example the name i is bound to the value 5. Binding different values to the name jdoes not have any effect on i, so when you later print the value of i the value is still 5.
1 2 3 4
i = 5 j = i j = 3 print(i)
In the second example you bind both i and j to the same list object. When you modify the contents of the list, you can see the change regardless of which name you use to refer to the list.
1 2 3 4
i = [1,2,3] j = i i[0] = 5 print(j)
Note that it would be incorrect if you said “both lists have changed”. There is only one list but it has two names (i and j) that refer to it.
We can easily do numeric operations in Python — actually you can take it as a simple calculator!
Basic mathematic operators
Operator
Description
+
add
-
subtract
*
multiply
/
divide
**
Exponentiation
( )
parentheses
//
floor division
%
modulo, find the remainder
Operator precedence
Highest to lowest precedence rule
Parenthesis are always with highest priority
Power
Multiplication, division and remainder
Addition and subtraction
Left to right
Logical operators
Logical operators can be used to combine several logical expressions into a single expression
Python has three logical operators: not, and, or
Comparison operators
Boolean expressions ask a question and produce a Yes/No result, which we use to control program flow. Boolean expressions use comparison operators to evaluate Yes/No or True/False.
Comparison operators check variables but do not change the values of variables.
Operators
Description
x < y
Is x less than y?
x <= y
Is x less than or equal to y?
x == y
Is x equal to y?
x >= y
Is x greater than or equal to y?
x > y
Is x greater than y?
x != y
Is x not equal to y?
Careful!! “=“ is used for assignment
Indentation
Increase indent: indent after an if or for statement (after :)
Maintain indent: to indicate the scope of the block (which lines are affected by the if/for)
Decrease indent: to back to the level of the if statement or for statement to indicate the end of the block
Blank lines are ignored – they do not affect indentation
Comments on a line by themselves are ignored w.r.t. indentation
Evaluate
The eval() function takes a string argument and evaluates that string as a Python expression, i.e., just as if the programmer had directly entered the expression as codeThe function returns the result of that expression.
eval() gives the programmers the flexibility to determine what to execute at run-time.
One should be cautious about using it in situations where users could potentially cause problems with “inappropriate” input.
Data Type
Numbers
Python supports four different numerical types −
int (signed integers)
float (floating point real values)
complex (complex numbers)
Please be noted that, if you do something like int(1.23), no exception will be raised. Instead, it will return an int object with value 1. The int class do the converion — assign the integer only.
Floating point real values
Floating-point numbers (float type) are numbers with a decimal point or an exponent (or both). Examples are 5.0, 10.24, 0.0, 12. and .3. We can use scientific notation to denote very large or very small floating-point numbers, e.g. 3.8 x 10^15. The first part of the number, 3.8, is the mantissa and 15 is the exponent. We can think of the exponent as the number of times we have to move the decimal point to the right to get to the actual value of the number.
In Python, we can write the number 3.8 x 10^15 as 3.8e15 or 3.8e+15. We can also write it as 38e14or .038e17. They are all the same value. A negative exponent indicates smaller numbers, e.g. 2.5e-3is the same as 0.0025. Negative exponents can be thought of as how many times we have to move the decimal point to the left. Negative mantissa indicates that the number itself is negative, e.g. -2.5e3 equals -2500 and -2.5e-3 equals -0.0025.
Here we should take care that, the implement of float in Python causes the incorrection. float(3.2)is not actually 3.2, but 3.200000000000000123 or something else. It does not matter in normal application, but when you are doing some scientific calculation, you may use some third-party packages to avoid it.
List
Lists are the most versatile of Python’s compound data types. A list contains items separated by commas and enclosed within square brackets ([]). To some extent, lists are similar to arrays in C. One difference between them is that all the items belonging to a list can be of different data type.
The values stored in a list can be accessed using the slice operator ([ ] and [:]) with indexes starting at 0 in the beginning of the list and working their way to end -1. The plus (+) sign is the list concatenation operator, and the asterisk (*) is the repetition operator.
For example,
1 2 3 4 5 6 7 8 9
>> List = [1, 2, "3", int(4.2)] # This name is lawful. The list data type (which is actually a class) is named "list" not "List" >> List[0] # Access the first element in the list. Note that in Python, almost everything starts at 0. 1 >> List[0:2] # Access what? Can you still remember? [1, 2] >> List[0:3:2] # Still, what is that? [1, '3'] >> List[-1] # Access the last element. 4
Slice Operator
What is a slice operator? The slice operator ([ ] and [:]) is to slice a list (of course).
It’s pretty simple really:
a[start:end] # items start through end-1
a[start:] # items start through the rest of the array
a[:end] # items from the beginning through end-1
a[:] # a copy of the whole array
There is also the step value, which can be used with any of the above:
a[start:end:step] # start through not past end, by step
The key point to remember is that the :end value represents the first value that is not in the selected slice. So, the difference beween end and start is the number of elements selected (if step is 1, the default).
The other feature is that start or end may be a negative number, which means it counts from the end of the array instead of the beginning. So:
a[-1] # last item in the array
a[-2:] # last two items in the array
a[:-2] # everything except the last two items
Python is kind to the programmer if there are fewer items than you ask for. For example, if you ask for a[:-2] and a only contains one element, you get an empty list instead of an error. Sometimes you would prefer the error, so you have to be aware that this may happen.
A tuple is another sequence data type that is similar to the list. A tuple consists of a number of values separated by commas. Unlike lists, however, tuples are enclosed within parentheses.
The main differences between lists and tuples are: Lists are enclosed in brackets ( [ ] ) and their elements and size can be changed, while tuples are enclosed in parentheses ( ( ) ) and cannot be updated. Tuples can be thought of as read-only lists.
String
Strings in Python are identified as a contiguous set of characters represented in the quotation marks. Python allows for either pairs of single or double quotes. Subsets of strings can be taken using the slice operator ([ ] and [:] ) with indexes starting at 0 in the beginning of the string and working their way from -1 at the end.
The plus (+) sign is the string concatenation operator and the asterisk (*) is the multiple concatenation operator.
For example,
s = 'Hello' + 'LGU' # s = 'HelloLGU'
s = 'A'*10 # s = 'AAAAAAAAAA'
String is essentially a list in Python, or more accurately, is a tuple. If we want to update a string, what can we do?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
s = 'Hello LGU'
# If we want to make it into 'Hello.LGU' # Can we do the following operation? s[5] = '.' # No, we cannot update a string. Instead, we can only assign a new string to it. s = 'Hello.LGU' # Interesting that we can do something like it... s = s.replace(' ', '.')
# Since string is a list, we can do the date type convertion here. >> print(list(s)) ['H', 'e', 'l', 'l', 'o', '.', 'L', 'G', 'U'] # OR... >> print(str(['H', 'e', 'l', 'l', 'o', '.', 'L', 'G', 'U'])) 'Hello.LGU'
Dictionaries
Python’s dictionaries are kind of hash table type. They work like associative arrays or hashes found in Perl and consist of key-value pairs. A dictionary key can be almost any Python type, but are usually numbers or strings. Values, on the other hand, can be any arbitrary Python object. Amazing, the value can be almost any Python data type too!
Dictionaries are enclosed by curly braces ({ }) and values can be assigned and accessed using square braces ([]). The elements in a dict is unsorted.
Example:
d = {'lgu': 'cuhksz',
'cuhk': 'shatin',
631: ['Guangdong', 'Zhejiang']}
print(d) # what will be printed?
d[0] # No suce operator. What is the first element in dict? I don't know. God know.
We can also loop a dictionary.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
>> for element in d: # If we do so, the element will be the KEY not a key-value pair. >> print(element) cuhk lgu 631 >> for key, value in d.items(): # Now the key and value is the correct pair. >> print(key, value) cuhk shatin lgu cuhksz 631 ['Guangdong', 'Zhejiang'] >> for value in d.values(): # Would like to loop the values? >> print(value) 'shatin' 'cuhksz' ['Guangdong', 'Zhejiang']
Boolean (bool)
Python contains a built-in Boolean type, which takes two values True/False
Number 0 can also be used to represent False. All other numbers represent True.
Sometimes, you may need to perform conversions between the built-in types. To convert between types, you simply use the type name as a function. Most conversion has been shown above.
In procedurally written code, the computer usually executes instructions in the order that they appear. However, this is not always the case. One of the ways in which programmers can change the flow of control is the use of selection control statements.
Selection statements allows a program to choose when to execute certain instructions. For example, a program might choose how to proceed on the basis of the user’s input. As you will be able to see, such statements make a program more versatile.
Selection: if statement
People make decisions on a daily basis. What should I have for lunch? What should I do this weekend? Every time you make a decision you base it on some criterion. For example, you might decide what to have for lunch based on your mood at the time, or whether you are on some kind of diet. After making this decision, you act on it. Thus decision-making is a two step process – first deciding what to do based on a criterion, and secondly taking an action.
Decision-making by a computer is based on the same two-step process. In Python, decisions are made with the if statement, also known as the selection statement. When processing an ifstatement, the computer first evaluates some criterion or condition. If it is met, the specified action is performed. Here is the syntax for the if statement:
1 2
if condition: if_body
When it reaches an if statement, the computer only executes the body of the statement only if the condition is true. Here is an example in Python, with a corresponding flowchart:
1 2
if age < 18: print("Cannot vote")
None
As we can see from the flowchart, the instructions in the if body are only executed if the condition is met (i.e. if it is true). If the condition is not met (i.e. false), the instructions in the if body are skipped.
The else clause
An optional part of an if statement is the else clause. It allows us to specify an alternative instruction (or set of instructions) to be executed if the condition is not met:
1 2 3 4
if condition: if_body else: else_body
To put it another way, the computer will execute the if body if the condition is true, otherwise it will execute the else body. In the example below, the computer will add 1 to x if it is zero, otherwise it will subtract 1 from x:
1 2 3 4
if x == 0: x += 1 else: x -= 1
This flowchart represents the same statement:
None
The computer will execute one of the branches before proceeding to the next instruction.
Value vs identity
So far, we have only compared integers in our examples. We can also use any of the above relational operators to compare floating-point numbers, strings and many other types:
1 2 3 4 5 6 7
# we can compare the values of strings if name == "Jane": print("Hello, Jane!")
# ... or floats if size < 10.5: print(size)
When comparing variables using ==, we are doing a value comparison: we are checking whether the two variables have the same value. In contrast to this, we might want to know if two objects such as lists, dictionaries or custom objects that we have created ourselves are the exact same object. This is a test of identity. Two objects might have identical contents, but be two different objects. We compare identity with the is operator:
1 2 3 4 5 6 7 8
a = [1,2,3] b = [1,2,3]
if a == b: print("These lists have the same value.")
if a is b: print("These lists are the same list.")
It is generally the case (with some caveats) that if two variables are the same object, they are also equal. The reverse is not true – two variables could be equal in value, but not the same object.
To test whether two objects are not the same object, we can use the is not operator:
1 2
if a isnot b: print("a and b are not the same object.")
Note: In many cases, variables of built-in immutable types which have the same value will also be identical. In some cases this is because the Python interpreter saves memory (and comparison time) by representing multiple values which are equal by the same object. You shouldn’t rely on this behaviour and make value comparisons using is – if you want to compare values, always use ==.
Nested if statements
In some cases you may want one decision to depend on the result of an earlier decision. For example, you might only have to choose which shop to visit if you decide that you are going to do your shopping, or what to have for dinner after you have made a decision that you are hungry enough for dinner.
None
In Python this is equivalent to putting an if statement within the body of either the if or the else clause of another if statement. The following code fragment calculates the cost of sending a small parcel. The post office charges R5 for the first 300g, and R2 for every 100g thereafter (rounded up), up to a maximum weight of 1000g:
else: print("Maximum weight for small parcel exceeded.") print("Use large parcel service instead.")
Note that the bodies of the outer if and else clauses are indented, and the bodies of the inner ifand else clauses are indented one more time. It is important to keep track of indentation, so that each statement is in the correct block. It doesn’t matter that there’s an empty line between the last line of the inner if statement and the following print statement – they are still both part of the same block (the outer if body) because they are indented by the same amount. We can use empty lines (sparingly) to make our code more readable.
The elif clause and if ladders
The addition of the else keyword allows us to specify actions for the case in which the condition is false. However, there may be cases in which we would like to handle more than two alternatives. For example, here is a flowchart of a program which works out which grade should be assigned to a particular mark in a test:
None
We should be able to write a code fragment for this program using nested if statements. It might look something like this:
1 2 3 4 5 6 7 8 9 10
if mark >= 80: grade = A else: if mark >= 65: grade = B else: if mark >= 50: grade = C else: grade = D
This code is a bit difficult to read. Every time we add a nested if, we have to increase the indentation, so all of our alternatives are indented differently. We can write this code more cleanly using elif clauses:
1 2 3 4 5 6 7 8
if mark >= 80: grade = A elif mark >= 65: grade = B elif mark >= 50: grade = C else: grade = D
Now all the alternatives are clauses of one if statement, and are indented to the same level. This is called an if ladder. Here is a flowchart which more accurately represents this code:
None
The default (catch-all) condition is the else clause at the end of the statement. If none of the conditions specified earlier is matched, the actions in the else body will be executed. It is a good idea to include a final else clause in each ladder to make sure that we are covering all cases, especially if there’s a possibility that the options will change in the future. Consider the following code fragment:
if department_name: print("Department: %s" % department_name)
What if we unexpectedly encounter an informatics course, which has a course code of "INF"? The catch-all else clause will be executed, and we will immediately see a printed message that this course code is unsupported. If the else clause were omitted, we might not have noticed that anything was wrong until we tried to use department_name and discovered that it had never been assigned a value. Including the else clause helps us to pick up potential errors caused by missing options early.
If statement in one line?
Look back to the previoud example.
1 2 3 4
if x == 0: x += 1 else: x -= 1
It is clear, but it takes 4 lines. Some may say, can I turn it into one line?
Of course you can :)
1
x += 1if x == 0else-1
The syntax is like true-statement if expression else false-statement. It is easy to understand right? One reminder, make your code understandable.
Loop statement
A loop statement allows us to execute a statement or group of statements multiple times.
Python programming language provides following types of loops to handle looping requirements.
Loop Type
Description
while loop
Repeats a statement or group of statements while a given condition is TRUE. It tests the condition before executing the loop body.
for loop
Executes a sequence of statements multiple times and abbreviates the code that manages the loop variable.
nested loops
You can use one or more loop inside any another while, or for or loop.
Loop control statements change execution from its normal sequence. When execution leaves a scope, all automatic objects that were created in that scope are destroyed. Python supports the following control statements.
Control Statement
Description
break statement
Terminates the loop statement and transfers execution to the statement immediately following the loop.
continue statement
Causes the loop to skip the remainder of its body and immediately retest its condition prior to reiterating.
pass statement
The pass statement in Python is used when a statement is required syntactically but you do not want any command or code to execute.
While loop statement
A while loop statement in Python programming language repeatedly executes a target statement as long as a given condition is true.
The syntax of a while loop in Python programming language is −
1 2
while expression: statement(s)
Here, statement(s) may be a single statement or a block of statements with uniform indent. The condition may be any expression, and true is any non-zero value. The loop iterates while the condition is true. When the condition becomes false, program control passes to the line immediately following the loop. In Python, all the statements indented by the same number of character spaces after a programming construct are considered to be part of a single block of code. Python uses indentation as its method of grouping statements.
Key point of the while loop is that the loop might not ever run. When the condition is tested and the result is false, the loop body will be skipped and the first statement after the while loop will be executed.
The Infinite Loop
A loop becomes infinite loop if a condition never becomes FALSE. You must use caution when using while loops because of the possibility that this condition never resolves to a FALSE value. This results in a loop that never ends. Such a loop is called an infinite loop.
An infinite loop might be useful in client/server programming where the server needs to run continuously so that client programs can communicate with it as and when required.
For loop statements.
The for statement in Python has the ability to iterate over the items of any sequence, such as a list or a string.
1 2
for iterating_var in sequence: statements(s)
If a sequence contains an expression list, it is evaluated first. Then, the first item in the sequence is assigned to the iterating variable iterating_var. Next, the statements block is executed. Each item in the list is assigned to iterating_var, and the statement(s) block is executed until the entire sequence is exhausted.
The range() function
The built-in function range() is the right function to iterate over a sequence of numbers. It generates an iterator of arithmetic progressions. For details please read the built-in help using help(range).
Using else Statement with Loops
Python supports to have an else statement associated with a loop statement.
If the else statement is used with a for loop, the else statement is executed when the loop has exhausted iterating the list.
If the else statement is used with a while loop, the else statement is executed when the condition becomes false.
Exception
An exception is an event, which occurs during the execution of a program that disrupts the normal flow of the program’s instructions. In general, when a Python script encounters a situation that it cannot cope with, it raises an exception. An exception is a Python object that represents an error.
When a Python script raises an exception, it must either handle the exception immediately otherwise it terminates and quits.
Handling an exception
If you have some suspicious code that may raise an exception, you can defend your program by placing the suspicious code in a try: block. After the try: block, include an except: statement, followed by a block of code which handles the problem as elegantly as possible.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
try: You do your operations here ..................... except: if there is any exception, then execute this block. except ExceptionI: If there is ExceptionI, then execute this block. except ExceptionII: If there is ExceptionII, then execute this block. ...................... except (Exception1[, Exception2[,...ExceptionN]]]): If there is exceptions, then … else: If there is no exception then execute this block. finally: This would always be executed.
Here are few important points about the above-mentioned syntax −
A single try statement can have multiple except statements. This is useful when the try block contains statements that may throw different types of exceptions.
You can also provide a generic except clause, which handles any exception.
After the except clause(s), you can include an else-clause. The code in the else-block executes if the code in the try: block does not raise an exception.
The else-block is a good place for code that does not need the try: block’s protection.
Raise an exception
You can raise exceptions in several ways by using the raise statement. The general syntax for the raise statement is as follows.
raise [Exception [, args [, traceback]]]
Here, Exception is the type of exception (for example, NameError) and argument is a value for the exception argument. The argument is optional; if not supplied, the exception argument is None.
The final argument, traceback, is also optional (and rarely used in practice), and if present, is the traceback object used for the exception.
Functions
A function is a block of organized, reusable code that is used to perform a single, related action. Functions provide better modularity for your application and a high degree of code reusing.
As you already know, Python gives you many built-in functions like print(), etc. but you can also create your own functions. These functions are called user-defined functions.
The names of built-in functions are usually considered as new reserved words, i.e. we do not use them as variable namesThe names of built-in functions are usually considered as new reserved words, i.e. we do not use them as variable names.
Defining a Function
You can define functions to provide the required functionality. Here are simple rules to define a function in Python.
Function blocks begin with the keyword def followed by the function name and parentheses ( ( ) ).
Any input parameters or arguments should be placed within these parentheses. You can also define parameters inside these parentheses.
The first statement of a function can be an optional statement - the documentation string of the function or docstring.
The code block within every function starts with a colon (:) and is indented.
The statement return [expression] exits a function, optionally passing back an expression to the caller. A return statement with no arguments is the same as return None.
If one function does not return a value, it is a void function. Return None by default.
1 2 3 4 5
deffunctionname( parameters ): "function_docstring" function_suite return [expression] print(abc) # no usage. the function exited by return statement.
Function Arguments
You can call a function by using the following types of formal arguments:
Required arguments
Keyword arguments
Default arguments
Variable-length arguments
Required arguments
Required arguments are the arguments passed to a function in correct positional order. Here, the number of arguments in the function call should match exactly with the function definition.
Keyword arguments
Keyword arguments are related to the function calls. When you use keyword arguments in a function call, the caller identifies the arguments by the parameter name.
This allows you to skip arguments or place them out of order because the Python interpreter is able to use the keywords provided to match the values with parameters.
The following example gives clear picture. Note that the order of parameters does not matter.
1 2 3 4 5 6 7 8 9 10
#!/usr/bin/python3 # Function definition is here defprintinfo( name, age ): "This prints a passed info into this function" print ("Name: ", name) print ("Age ", age) return
# Now you can call printinfo function printinfo( age=50, name="miki" )
Default arguments
A default argument is an argument that assumes a default value if a value is not provided in the function call for that argument. The following example gives an idea on default arguments, it prints default age if it is not passed.
1 2 3 4 5 6 7 8
defprintinfo( name, age = 35 ): "This prints a passed info into this function" print ("Name: ", name) print ("Age ", age) return # Now you can call printinfo function printinfo( age=50, name="miki" ) printinfo( name="miki" )
Variable-length arguments
You may need to process a function for more arguments than you specified while defining the function. These arguments are called variable-length arguments and are not named in the function definition, unlike required and default arguments.
Syntax for a function with non-keyword variable arguments is this −
An asterisk (*) is placed before the variable name that holds the values of all non-keyword variable arguments. This tuple remains empty if no additional arguments are specified during the function call. Following is a simple example −
1 2 3 4 5 6 7 8 9 10
defprintinfo( arg1, *vartuple ): "This prints a variable passed arguments" print ("Output is: ") print (arg1) for var in vartuple: print (var) return # Now you can call printinfo function printinfo( 10 ) printinfo( 70, 60, 50 )
The return Statement
The statement return [expression] exits a function, optionally passing back an expression to the caller. A return statement with no arguments is the same as return None.
Return multiple values
Python allows a function to return multiple values. The sort function returns two values; when it is invoked, you need to pass the returned values in a simultaneous assignment. Try to run it!
1 2 3 4 5 6 7 8
defsort(a, b): if a > b: return a, b else: return b, a